In my last Spiderfoot tutorial I wrote about how Spiderfoot HX could be used to gather information about a suspicious IP address and then analyse and visualise the data. In this guide I’m going to show how Spiderfoot HX can be used to investigate a domain linked to phishing.
Despite a lot of high-profile coverage of zero day exploits and advanced hacking techniques, phishing still remains the single most prevalent way for bad guys to carry out a cyber attack according to the National Cyber Security Centre. So it helps to be able to understand the infrastructure behind a phishing attack.
Target
The research target is a real phishing domain that was identified as being linked to malware distribution just a few days ago. Victims were targeted with a phishing e-mail that impersonated a real e-mail from FedEx:
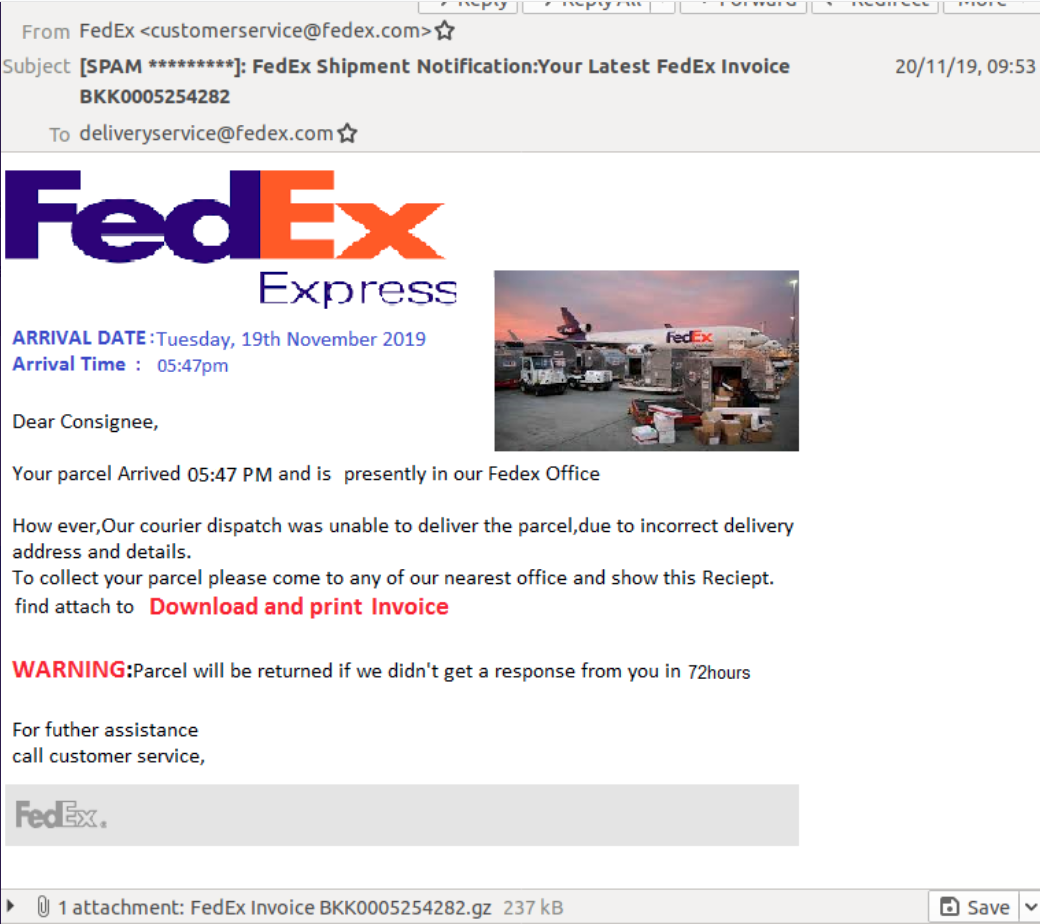
Opening the attachment installed some credential-stealing malware on the recipient’s device. You can see more of the analysis of the malware itself here (HT @dave_daves) but for now we’re going to focus on the domain that the malware was reporting back to:
hikmahmuliautama[.]co[.]id
In the rest of this guide we’ll look at how to prepare Spiderfoot HX to gather information about the domain and then evaluate what it finds.
Setting Up The Scan
In my last article I explained how to configure Spiderfoot HX to use API keys. Once they’re set up, they’re stored permanently so there’s no need to re-add them every time. For the scan itself, there are a couple of approaches we can take. Spiderfoot HX allows scans to be conducted either passively or by targeting the domain directly.
A passive search collects data from third party sources but never touches the target directly. This can be useful if you don’t want the target to have any indication of your scan in their logs. A passive scan still brings back a lot of detailed information too.
Alternatively it’s possible to conduct a scan either with all modules enabled, or with some selected modules enabled. In this case we want to find out everything we can about the target domain, so I’m going to set up an active scan with some modules specifically chosen for the task.
If you’re concerned about your scanning activity being detected by your target, Spiderfoot HX makes it possible to route all the scans via TOR. The target will still see they are being scanned, but the source IPs will be that of TOR exit nodes. Scanning through SpiderFoot HX is anyhow anonymous, but this can be an additional measure in case you are extra paranoid. To enable TOR, simply go to Configure > General and change “Use of TOR for tunnelling HTTP/HTTPS requests” to True:

After saving changes, your next scan will be conducted via TOR. I’ve found when using this option that although it is slightly slower, there was no impact on the amount of data returned.
There’s no need to enable every single module to conduct a scan of our target domain. Some of them aren’t relevant to the task and there’s no point causing the scan to take longer than necessary or using those precious API credits unnecessarily.
Enable modules you want by selecting New Scan > Select Individual Modules. For this scan I’ve chosen a few modules that will scan the target quite aggressively – I want to know everything that I can. These two modules will conduct DNS brute force, for instance:

And given the nature of the phishing attack, I certainly want to check out results from Fraudguard too:
![]()
The Page Info module will also grab HTML data from the target directly to determine what kind of content is hosted so that I don’t have to visit it from my own machine:
![]()
Overall Spiderfoot has about 170 different modules that you can enable or disable as needed. When you’ve enabled the modules that you want, you can save the configuration as a Scan Profile to reuse for future scans.
Correlations
There’s one more thing to prepare before starting the scan. How do we make sense of the huge amounts of data that Spiderfoot HX is likely to return? Gathering information is one thing, but in real-life OSINT what matters is being able to analyse data and draw sound conclusions quickly. Later in this guide we’ll see how Spiderfoot HX’s visualisation tools help to do part of this, but setting up the Correlations tool at the start will also help pinpoint the key data we want when the scan is complete.
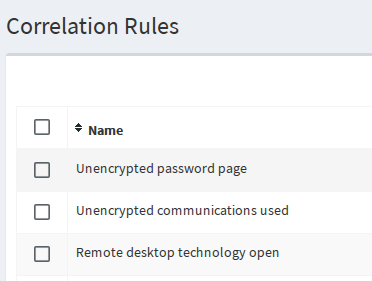
Correlations detect when scan results meet a certain set of rules, reported separately from the scan results so you can focus your attention there first. For example if Spiderfoot detects that a website features an unencrypted password page, this can be immediately brought to the user’s attention with a risk-rated correlation rule. You might want to enable this if you were conducting a penetration test, for example.

The level of risk assigned to each correlation rule is fully customisable according to your need. Spiderfoot HX will flag anything that meets the correlation rule conditions, so setting it up carefully at the outset will help to pinpoint the important details at the end. Changing correlation rules applies to all future scans, so you don’t need to configure them per-scan.
It’s safe to just leave all rules enabled, and as the volume should be low, it’s fairly simple to browse them when the scan is completed.
We’re ready to start the scan and let it run. Spiderfoot HX runs on its own cloud server so you can let the scan run by itself and receive an e-mail notification when it’s completed (unless you disable that option). Results are also returned in real time so you don’t need to wait for the scan to complete before reviewing the data.
Analysis
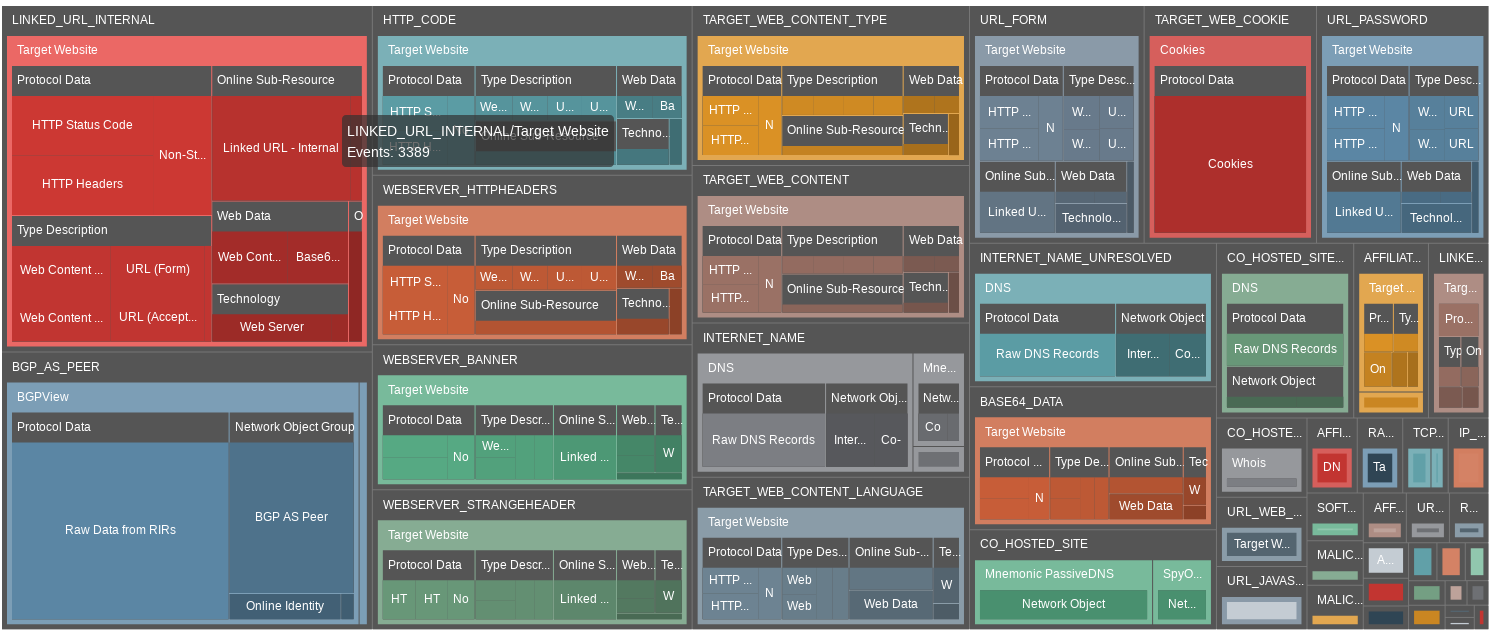
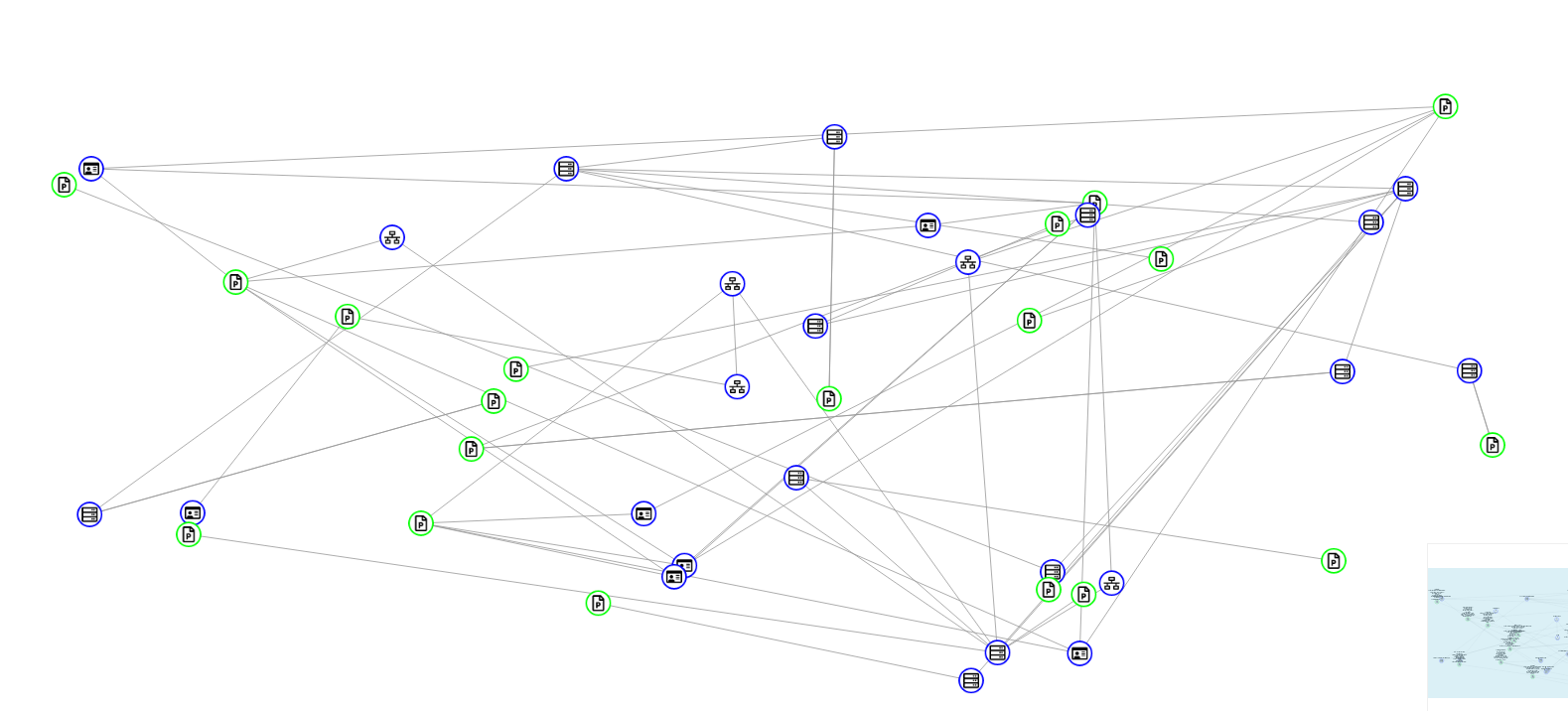
Visualisation of the entire scan results in Tree Graph mode
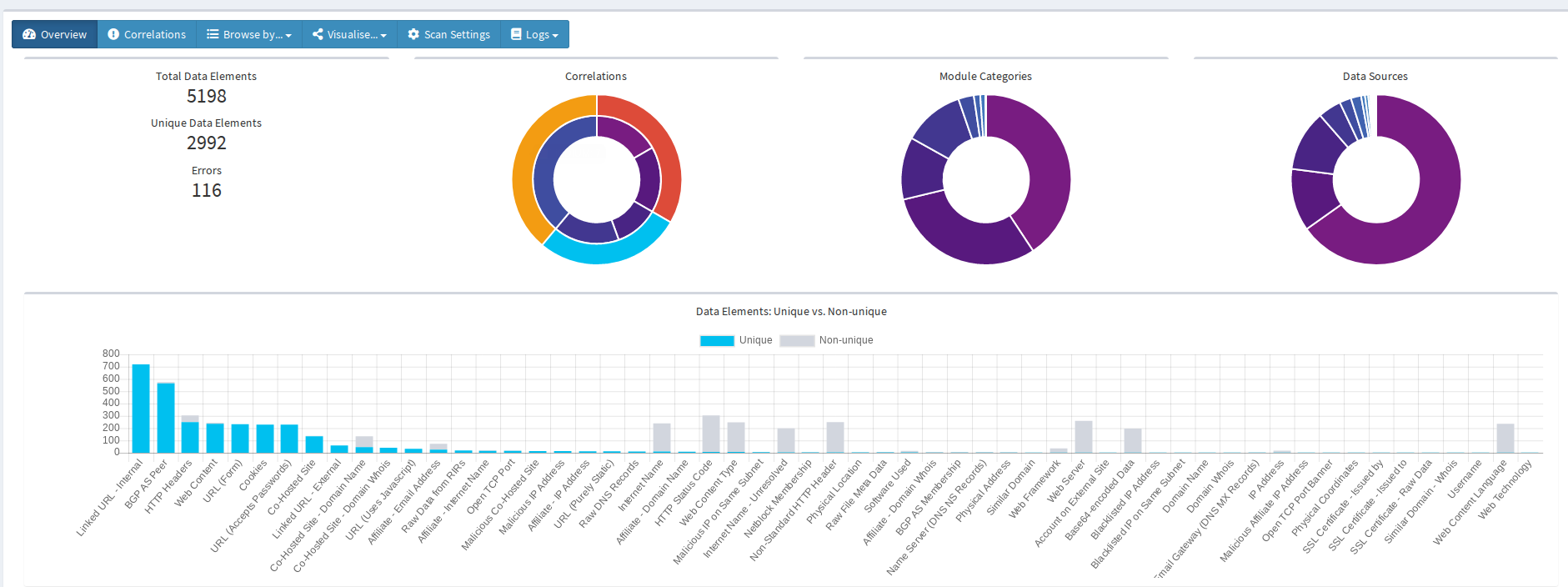
It’s immediately clear why the correlations feature is so important. Scanning the target domain has returned more than 5000 pieces of information, but the correlations feature will ensure that we can focus on the most important ones first.

The correlations are colour-coded according to risk level. You can click on each one to learn more about the results. These are the results that Spiderfoot HX has flagged as being of high concern:
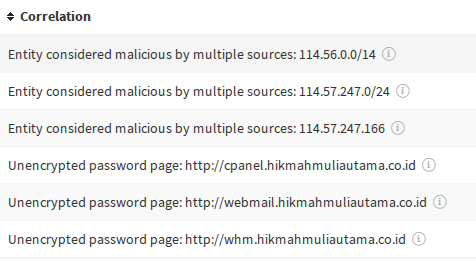
Spiderfoot HX has identified three subdomains on the target host that prompt for passwords but are unencrypted – an immediate red flag from a security point of view. The scan has also indicated that the host IP address and and its wider subnet are considered malicious by multiple sources. We can use Spiderfoot HX’s visualisation features to get a better understanding of this:
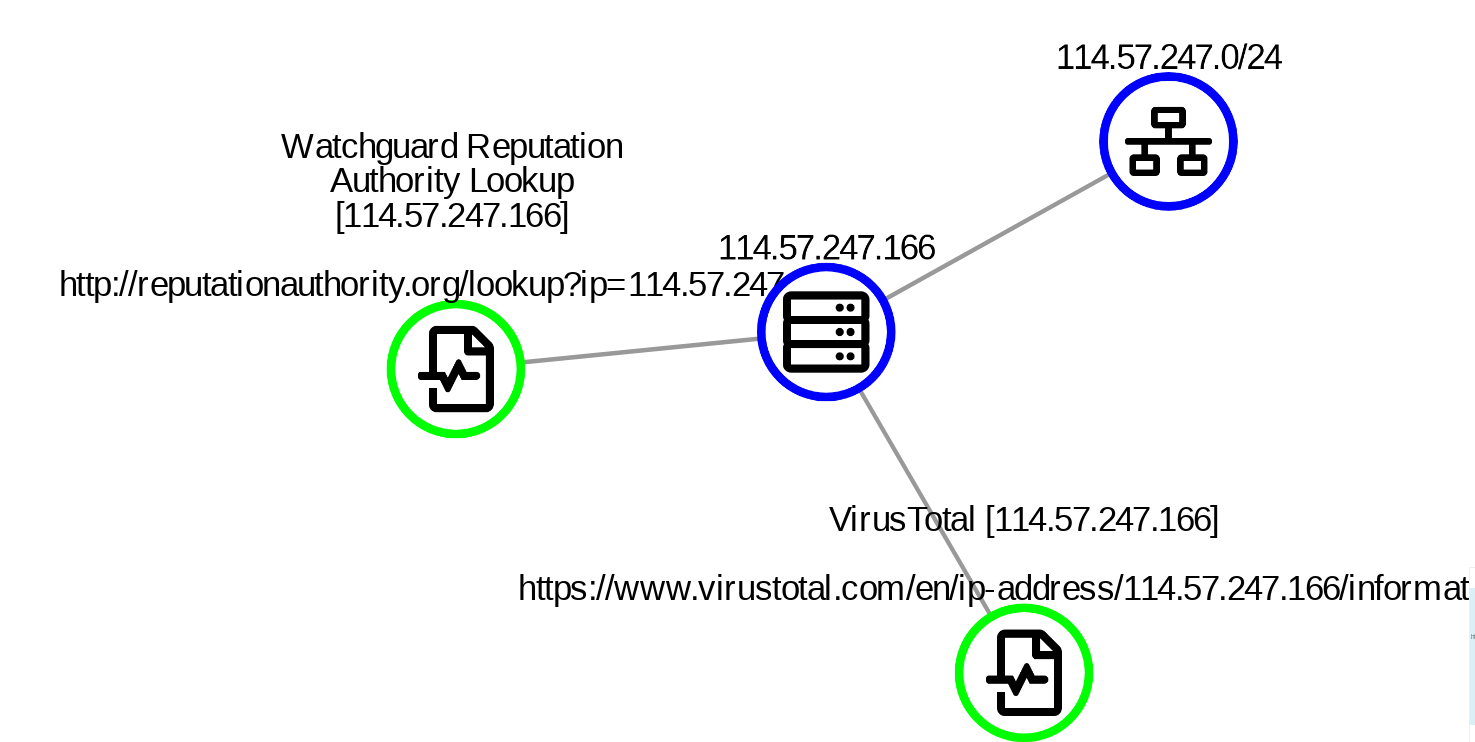
To visualise this search result, click on the number in the Data Elements column, then select the visualisation technique of your choice from the drop down menu. The image above is the All Data Node Graph (Random) visualisation.
This is the same data visualised with the Connectivity Chord option:
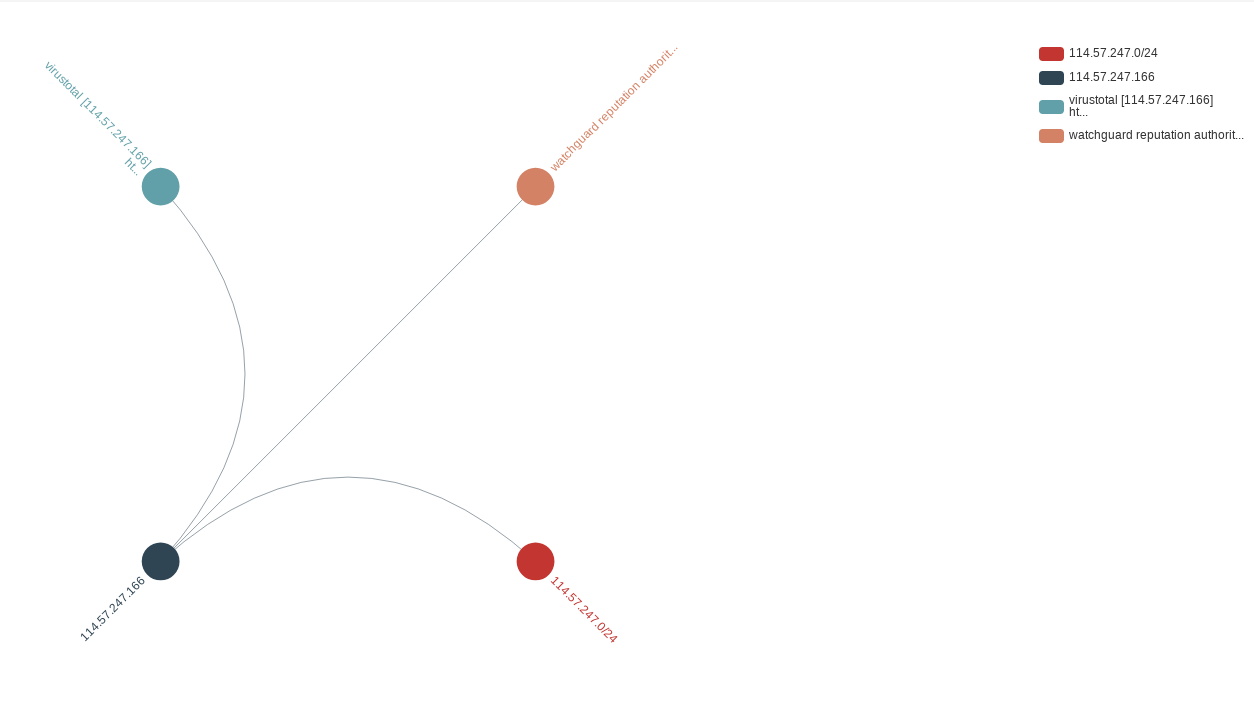
In the same way we can also visualise the wider malicious subnet:
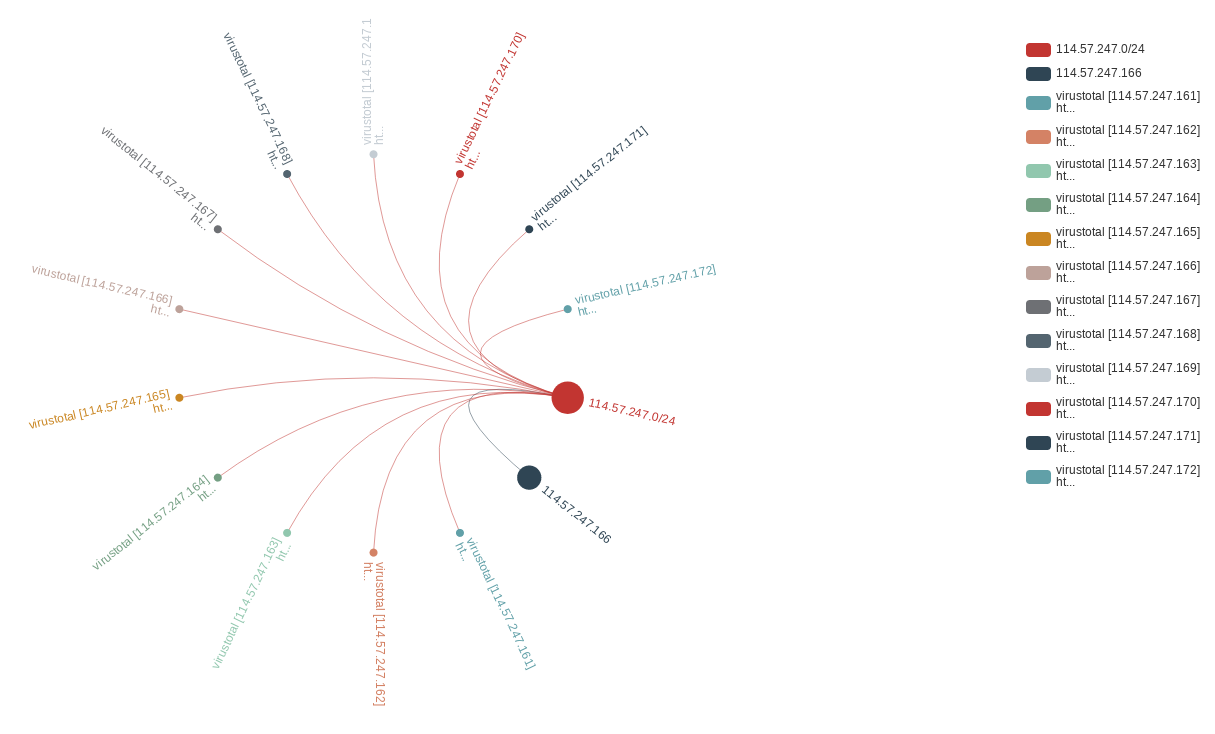
Ouch! There’s a VirusTotal report for 13 different IPs on this subnet. The fact that all the malicious IPs are in sequential order might also offer some clues as to how they became hosts for malicious activity in the first place. This pattern may indicate that a bot crawled a range of IPs systematically, and was able to exploit the same vulnerability over and over again. If this is the case, we might be looking at a compromised host rather than domain created specifically for a phishing campaign.
Following up the VirusTotal results also leads to some more useful information about the type of malware being distributed by the target domain. There’s no need for us to visit and sample it ourselves:
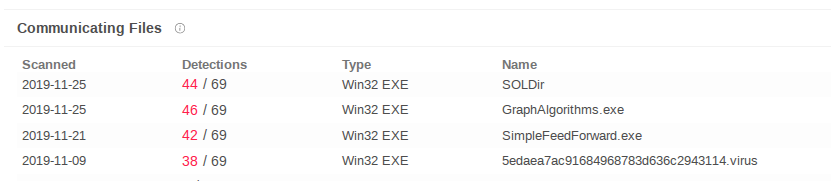
The Correlations feature in Spiderfoot HX really helps to focus on the important issues. Out of all the data returned, the areas of interest that we specified during the initial setup have been flagged up right away so we can make a quick assessment about the type of threat posed by this domain and its wider subnet.
Further Analysis
What about the rest of the scan results? There’s plenty of useful analysis to be done with these too. To see the rest of the results, go to Browse By > Data Type:
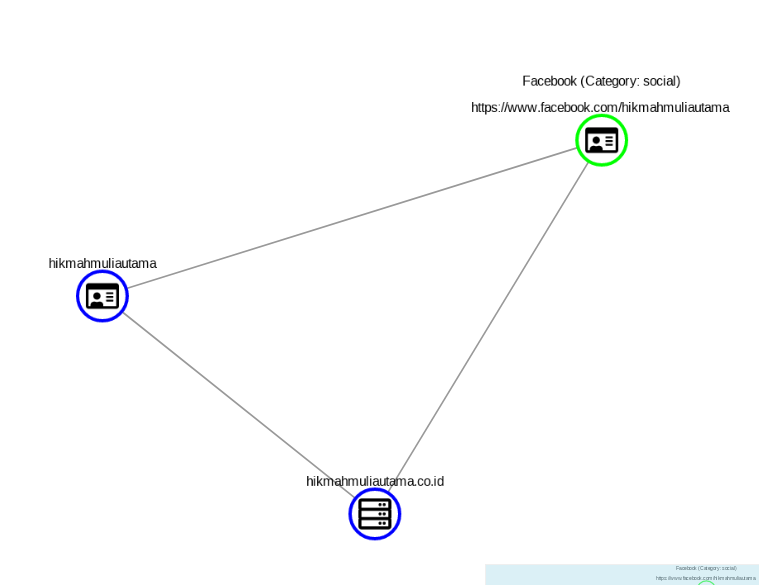
The amount of information retrieved by Spiderfoot HX is considerable and we can learn an awful lot about the target. One of the first results identifies a Facebook page associated to the domain:
There’s also an awful lot of open ports:

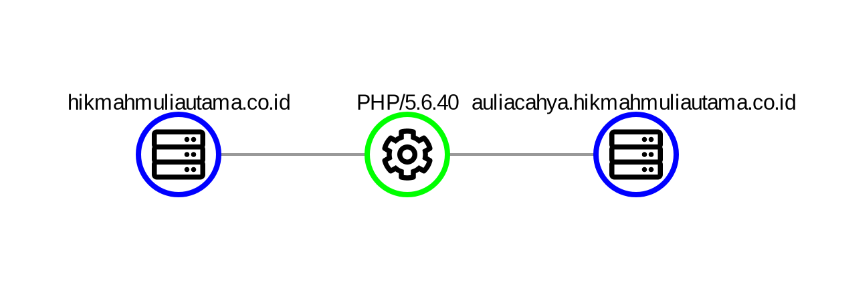
And use of vulnerable software with several well-known CVEs:
The RIR (Regional Internet Registry) results also contain a lot of useful data about the host, including Whois data, associated e-mail addresses, HTTP banners, and HTML content:
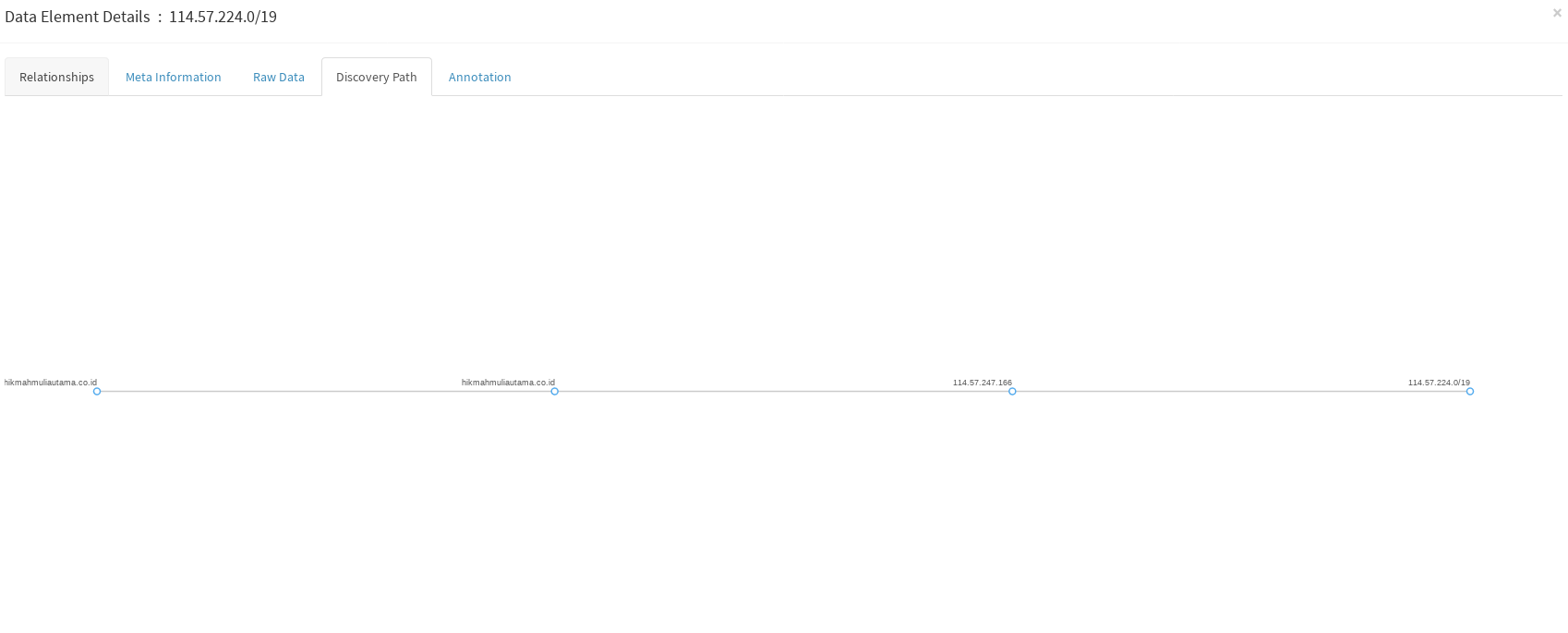
To view more detail about any of the nodes, just right-click and choose “Details” to see more information. Nodes of interest can be highlighted, and if you’re ever unsure how a particular node is connected to the original query, you can look at the Discovery Path to find out. Right click on a node > Details > Discovery Path.
Because we chose a targeted scan rather than just a passive scan, there’s a lot of information that comes directly from the target website itself. Spiderfoot HX discovered 229 different URLs that accept passwords, 236 different HTML pages, 249 headers, and details of 45 co-hosted domains which are themselves likely to have been compromised. That’s more than enough information to learn about the domain and how it’s used for phishing.
It’s possible to export any or all of these datasets into JSON, CSV or GEXF format for further analysis by clicking on the Export icon:
![]()
As you can see, Spiderfoot HX is highly customisable, very powerful, and it gathers a huge amount of data in a short amount of time so that users can spend more time analysing the data and actioning it rather than spending hours just gathering it.
So far in this series of Spiderfoot guides we’ve looked at malicious IP addresses and domains. In the next part I’ll explore how Spiderfoot HX can be used to research online profiles, phone numbers, and e-mail addresses – and how Spiderfoot HX’s monitoring feature can keep actively checking them as part of an OSINT investigation.