A few months ago I wrote about how you could use Carbon-14 to detect the timestamps for images published in webpages. By comparing the publication times of the images with the publication time of the page itself it is possible to construct a timeline of when various elements in webpage were put together and so detect any editorial changes. In my original post I used an example from my own website to show the concept but it’s much more interesting to do it with a real life case.
The Cropped Climate Activist
The Guardian reported yesterday about the controversy over the omission of black climate activist Vanessa Nakate from an article published by the Associated Press. After being accused of racism by cropping Nakate out of the photo, the AP published the original image in its place and removed the cropped image that had caused the offence. This was the original published photo with Nakate cropped out:

And here is the original, which was later added in its place:

I should be clear that the purpose of this article is not to argue about the rights and wrongs of what happened. I actively avoid political discussion on my blog and also on my Twitter account, and this will be no different. My aim is to show how it is possible to look at the underlying data that webpages leave to construct a timeline of events and detect editorial changes in website content. In the case of the AP article, there most definitely was an editorial change, although you would not know it if you visited the page directly. Let’s start at the beginning.
When Was The Article Published?
This might seem obvious, but the publication date is at the top of the article:

So the article was published on January 24th, 2020. This is nice to know, but it is not specific enough if the changes we are trying to detect all occurred in the same 24 hour period (which they did in this case). We need more detailed information. To get it right click on the page and choose “View Page Source” (or “View Source” in some browsers). Then choose Ctrl + F and search for the term “title”. This takes us to the part of the page that contains metadata about the publication time:
title="2020-01-24 10:41:09 - Fri Jan 24 2020 10:41:09 GMT+0000 (Coordinated Universal Time)">January 24, 2020 GMT<
So the article was published at 10:41:09 GMT on Friday 24th January 2020 – much more precise. We should expect that the photos that accompany the article were published at around the same time, but the photos in place now were not actually published until much later. By examining the content of the website in a little more detail we will be able to show categorically that the website was changed, and also find the original content that was removed.
Digging With Developer Mode
Modern websites are extremely complex, and a single webpage is made up of dozens or even hundreds of smaller components. There are CSS files to style the page, PNG and JPG files for images, Javascript to add dynamic content, cookies to track user interactions, JSON files of data retrieved via APIs, and so on. Your browser has to request and display every single one of these elements and assemble them together for you to view a webpage, and each element in a webpage contains its own metadata. By examining them individually it is possible to learn more about a website than is obvious at face value.
To view a site in developer mode, press F12 to open up the console. In this guide I’m using Firefox, but the process is identical in Chrome. We already know the publication time for the article from inspecting the source code, but we can build up the timeline of the controversy by turning to look at the Tweet which triggered AP to make a change to their webpage in the first place:
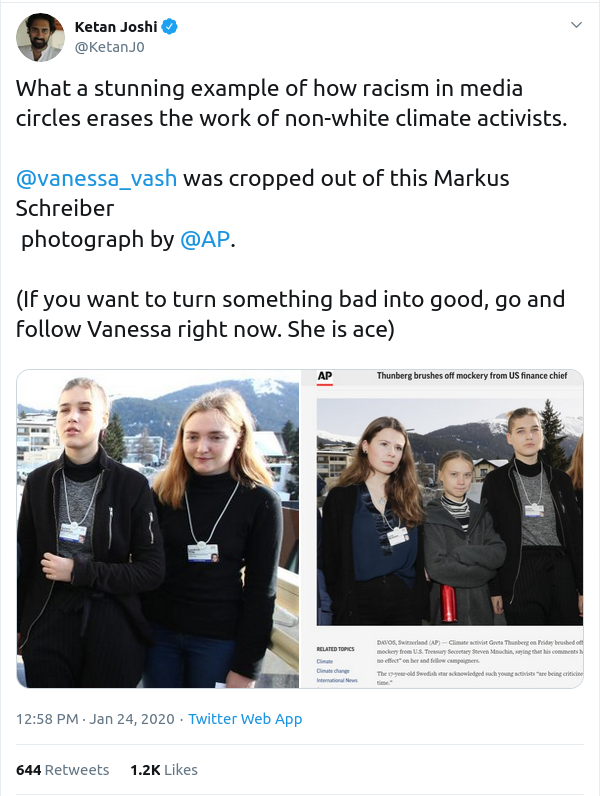
Here’s the URL for that tweet:
https://twitter.com/KetanJ0/status/1220692414458929154
To open developer mode, press F12 and visit the page. If you’ve already loaded it and you see nothing in the developer console, press Ctrl + R to reload it. Developer Mode offers vasts amounts of information about a webpage, but we’re only really interested in the Network information because it contains all the useful metadata we need. To see the Network data, click on the Network option in the developer toolbar:
![]()
Over to the right, there’s another smaller menu that looks like this:
![]()
This allows us to filter any content that we’re not interested in. For the purposes of this research, we only need to know about the HTML and Images data, so just select those. In the main developer window you’ll then see something like this:

This is a list of all the image and html elements in the tweet that we selected. They are presented in order that they were loaded. Clicking on the highlighted element gives us an insight into when the Tweet was posted:
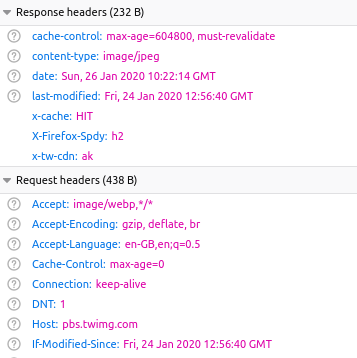
Note that this technique does not work with all elements in a webpage. If you try to see when HTML elements were published, the timestamp will show the time when you made the request to the browser, and not when the content was first uploaded. This is why images are so useful for establishing the age of website content because of they are posted to the web.
If you’re unsure as to which line in the console refers to which image, then you can just hover over it until you find the image you’re interested in, like this:
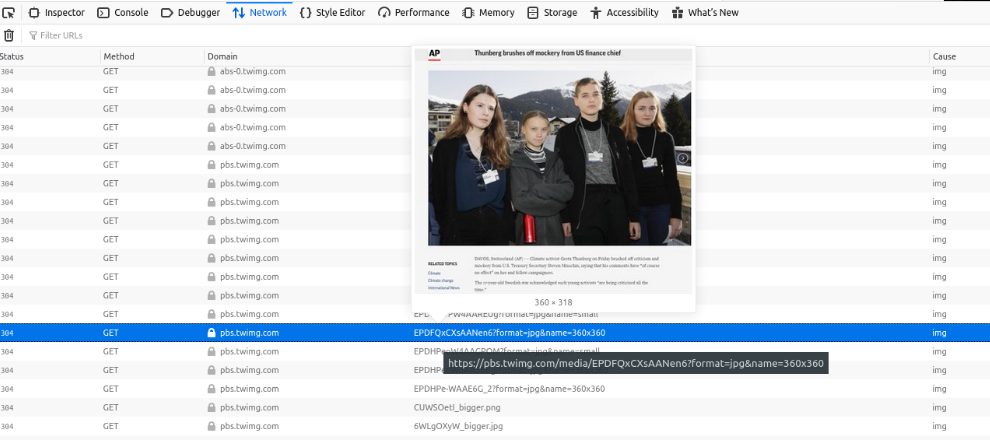
So our timeline now shows that the article was published at 10:41:09 GMT, and the critical tweet featured above was published at 12:56:40 GMT.
Dating Images In The AP Article
Now we can look at the actual AP article itself. The URL is below. I’ve posted it in full because it will help us later on:
https://apnews.com/ee36c1b18874d3ebec2c743f0968396f
The site now displays a different image to the cropped one that initially caused so many problems. It actually shows eight separate images that are displayed as part of a slideshow. To see the HTTP header information for all the images, open the developer console as before and click through all 8 to load them into the console. You’ll end up with something that looks like this:

These are the HTTP GET requests for each of the eight images (plus a thumbnail of the first image). Notice that they aren’t actually hosted on the AP site itself – they’re requested from a Google Cloud storage bucket. They also appear to have an identical filename of 1000.jpeg. This might seem confusing but we’ll look at the filename syntax shortly because this is what will provide us with stronger proof that a little editing took place. For now we can click on each HTTP request as before and see the publishing times of the images using the Last-Modified and If-Modified-Since headers. We can see from the Last-Modified header that of all of the eight pictures now present, this photo was uploaded first at 14:23:18 GMT:

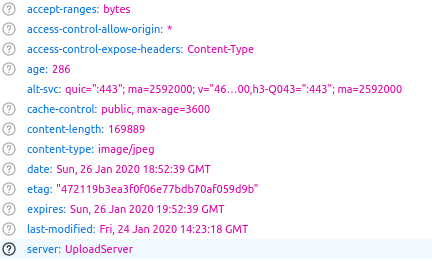
The last image in the slideshow was uploaded just a few minutes later at 14:27:57 GMT:
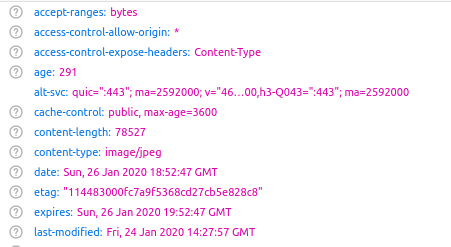
Notice that there is a date header that is distinct from the last-modified header. The date header is based on the time that the user visited the webpage and not when the content was actually published. (So you can actually work out exactly when I was conducting the research for this blog post!)
We’ve seen that these images weren’t uploaded until almost four hours after the original article was published. It’s a little odd for there to be such a gap, but by itself this isn’t proof that any changes were made. In fact if you’d just visited the website and were unaware of any of the earlier controversy, you’d never actually know that the images had been changed. Next we’ll look at what the URLs contained in the page can tell us about how the site is constructed – and ultimately help to find the original cropped image that was removed.
The Smoking Gun…
We’ve already seen from the URL requests that AP News does not host images on its own domain, they are stored in a Google Cloud bucket and requested from there. Google Cloud generates unique URLs for its cloud-hosted content that can be shared but which are unguessable. For example let’s pretend that Google did not serve content in this way. An AP News image URL would look something like this:
https://apnews.com/some-news-article/img003.jpg
You would then be able to predict that there would also be another image at
https://apsnews.com/some-news-article/img004.jpg
To avoid unwanted access to content held in its cloud storage, Google uses 32-character hexadecimal strings to form a URL. We can see this in the actual URL for the AP News article:
https://apnews.com/ee36c1b18874d3ebec2c743f0968396f
Using a 32-character hex string like this means that the URL is impossible to guess, since there are 1632 possible URL combinations (340282366920938463463374607431768211456, to be precise). This means there are a great deal more possible URL combinations than there are known stars in the observable universe (there are only a mere 100 billion trillion of those). This is really useful from an attribution point of view because it means there is no realistic chance that an identical URL string could be created independently. So where we can find this string in a URL we can have a high degree of confidence it originated from AP News’ Google Cloud, as we’ll see shortly.
The same method is used to create URLs for images on the site. Consider the URL for this picture as it appears in the AP News gallery:
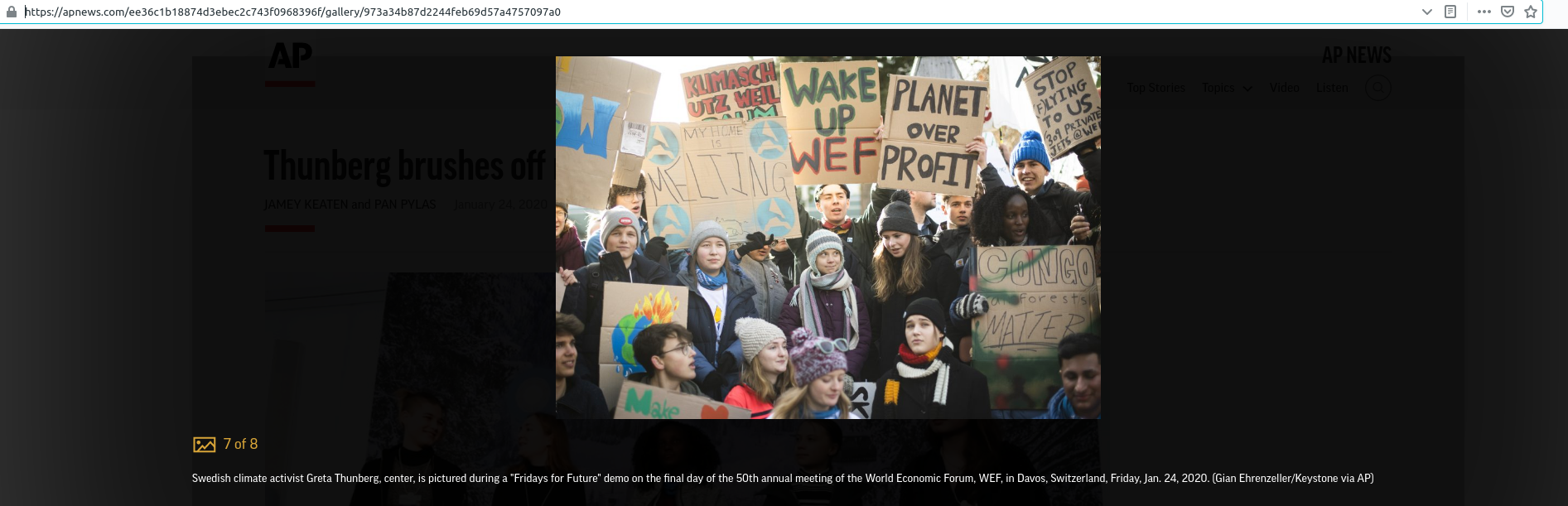
https://apnews.com/ee36c1b18874d3ebec2c743f0968396f/gallery/973a34b87d2244feb69d57a4757097a0
The URL format is https://apnews.com/UNIQUE_ARTICLE_STRING/gallery/UNIQUE_IMAGE_STRING. The article has its own 32-character URL, and so does each image attached to the gallery. We can use the uniqueness of these URL strings to search for related content across the web. Here are the results of a Google search for the unique article URL string ee36c1b18874d3ebec2c743f0968396f:
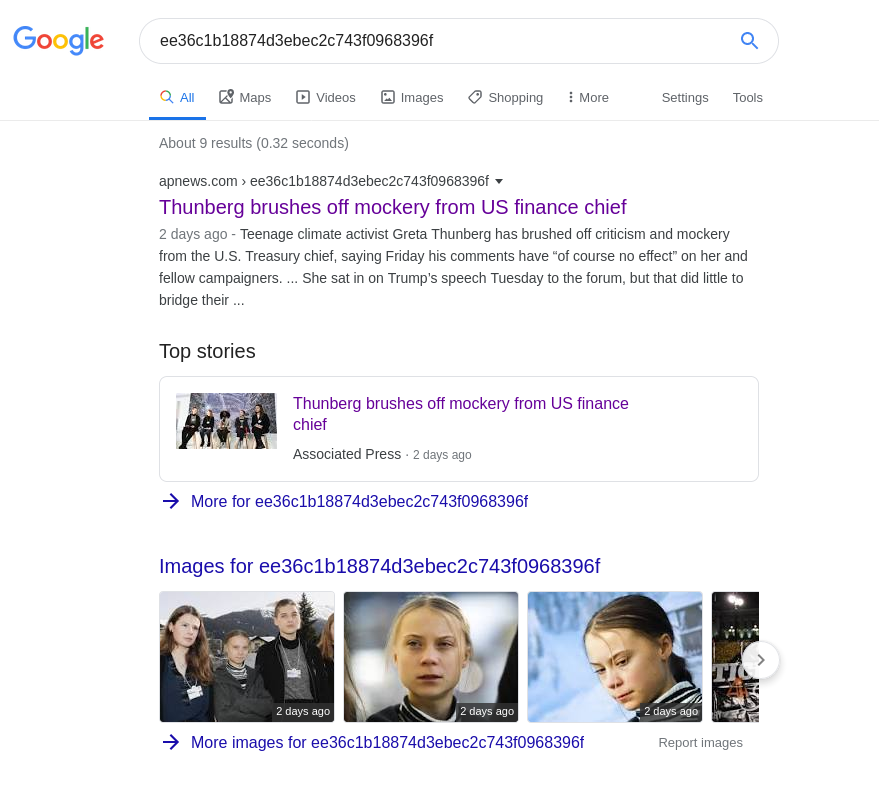
As expected the only results are for the article itself, or pages that link to it. Now look at what happens when we do a Google Image search for the same URL string:

The very first result is for the cropped photo that caused so much controversy – but it isn’t on the APNews website. It’s on a site that syndicates content originally published by AP News called The Public’s Radio. The relevant page now reflects the editorial changes made to the original AP content, with the same eight images present.

Even if it wasn’t clear from reading the page content, we can be absolutely certain that this content comes from the same source when we look at the URL for the images. Here is the URL for the image of the girls sitting on the chairs above:
https://content-prod-ripr.thepublicsradio.org/articles/ee36c1b18874d3ebec2c743f0968396f/4c81631a91fb4f7ea21714eb834ae4fc_1000.jpg
Now compare the URL for the same image on the AP News website when the image is viewed directly:
{kind=link}
https://storage.googleapis.com/afs-prod/media/4c81631a91fb4f7ea21714eb834ae4fc/1000.jpeg
And when viewed in gallery mode:
https://apnews.com/ee36c1b18874d3ebec2c743f0968396f/gallery/4c81631a91fb4f7ea21714eb834ae4fc
Notice that the same unique ID for the main article (ee36c1b18874d3ebec2c743f0968396f) and for the specific image (4c81631a91fb4f7ea21714eb834ae4fc) are the same on both websites. In this case there is little doubt that the content originated in the same place – but you can see how this technique could be useful to identify a common content source in cases where people were less transparent about what they were posting to the web.
This is all very interesting of course, but what has it got to do with the original premise of this article? Let’s have a look at the URL of the cropped image that we found when conducting a Google search for the unique URL. Here’s the image:
And here’s the URL:
https://content-prod-ripr.thepublicsradio.org/articles/ee36c1b18874d3ebec2c743f0968396f/b328402a14914e3981ea2926d73ef3e8.jpg
Notice the same unique hex string in the URL for this image? This shows that at one time this image must have been associated to all the other content that came from the AP article as was associated to the same string. The chances of it not being associated to the original AP article and somehow sharing the same identifier by chance are about 1 in 1632.
Let’s have a look at the HTTP headers for this image in the developer console to find out when it was published to the Public’s Radio site:
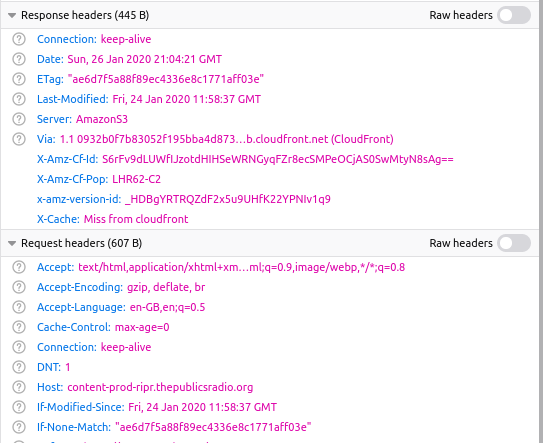
We can see that this image was published to The Public’s Radio site at 11:58:37 GMT, so it must have present on the AP website even before then, even if it has been replaced by images that were inserted into the AP article later in the afternoon of 24th January. We can confirm this by tweaking a known URL format to test our hypothesis. The unique string for the cropped image is b328402a14914e3981ea2926d73ef3e8, so let’s add that into a known AP URL and see what happens:
https://storage.googleapis.com/afs-prod/media/b328402a14914e3981ea2926d73ef3e8/1000.jpeg

Ta-da! The cropped image is still on the server, even if it is no longer available to view. There can be no doubt that this cropped image was once present in the AP article and has now been removed. We can also see the time it was originally uploaded:
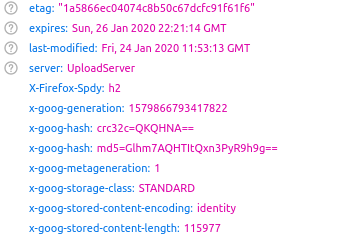
It was uploaded at 11:53:13 GMT, just five minutes before the same image appeared on The Public’s Radio.
Leaky EXIF Data
This article isn’t a whodunnit – no one is denying what took place or that a change was made – but it should be possible to reproduce this method to detect changes and manipulations when others are not so open about them.
Before I finish, I want to point out one more forensic golden nugget that I came across when researching this post. I’m not sure at what point it occurred, but when the image was published to the AP website, all the EXIF data was removed, just as it was for all the other published images. However for some reason I’m still not sure of, the EXIF data was not removed from the image that was uploaded to The Public Radio. To see this for yourself, download a copy of the image and upload it to Forensically. The EXIF data is still intact:
{kind=link}
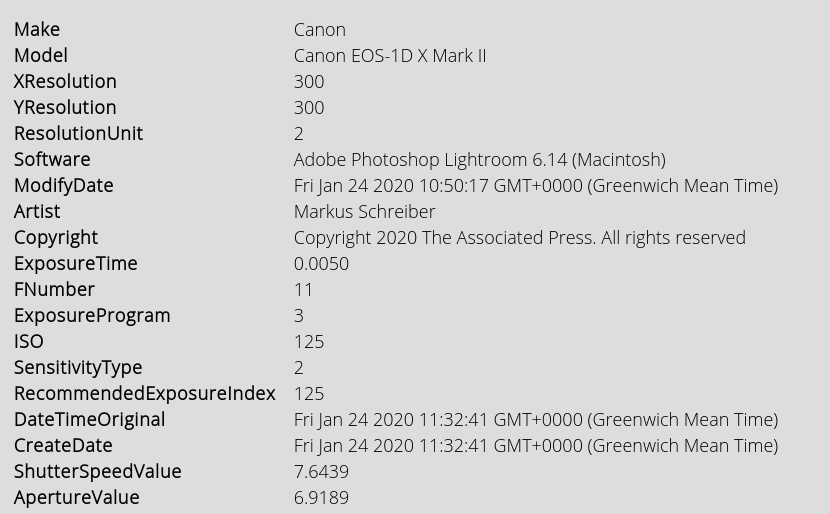
You might notice that the Modify date is before the CreateDate. I suspect (although I’m not 100% sure without further testing) that the image was actually uploaded to the photographer’s Macintosh at 10:50:17 GMT, and that it was subsequently edited at 11:32:41 GMT prior to being posted into the AP article at 11:53:13 GMT.
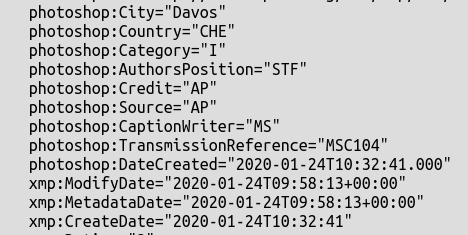
Forensically also picks out text strings in the image metadata that are of interest:

Further down we can actually there is an even earlier timestamp for the metadata creation itself – 09:58:13 GMT, so this may be when the image was actually taken. I don’t have access to Photoshop to verify the way that it creates and handles metadata, so feel free to correct me if I’ve erred at this point.:
It isn’t just this image either; I’ve noticed that the metadata of all the photos is still present if you access them with the following URL:
https://content-prod-ripr.thepublicsradio.org/articles/ee36c1b18874d3ebec2c743f0968396f/[UNIQUE IMAGE STRING].jpg
So this means that EXIF data is stripped from AP images quite far down the line, and that in some cases it is possible to recover it by crafting an alternative URL path to the image. This raises a lot of possibilities for further exploration of published press photos that appear to have had their metadata removed, but that’s probably for another post.
Though I have realized redoing all these steps especially when looking for the cropped image via unique ID for the main article, after almost a month since the correction was made, no results on the cropped image are present on google linked to AP or Public radio.