
One of the biggest challenges of internet investigation is preserving data once you’ve found it. We have access to more information than ever before, but so much of it can be easily lost if we don’t take steps to archive it. If you’ve ever bookmarked an important resource only to come back later and see that it’s no longer available, you’ll know how frustrating it can be. I wrote about this problem last year in this post about the Attrition of Information In OSINT along with some suggestions about how to preserve internet material as well as how to recover data when it has been removed.
The Internet Archive is probably the most familiar tool for preserving web pages but it is not without its limitations. It can’t capture Facebook pages for instance, and even if you instruct it to begin archiving a site then it can easily fail if that site’s robots.txt prevents crawling. The increasing use of Javascript and embedded video content also makes scraping and archiving webpages more difficult. The preserved site you find on the Internet Archive is often missing much of the original content and features.
To counter this it is necessary to use several types of tool to preserve web content for your investigations rather than just relying on one. Hunchly is excellent for capturing web pages, but I still like to supplement it with YouTube-dl for grabbing video content. Recently I’ve also started using Archive Box to build offline archives of web content that I want to keep. It wasn’t designed with OSINT work in mind but it is perfectly suited to the task of preserving and archiving web pages in multiple formats, including JavaScript-based websites and PDF/PNG screenshots. Video and audio content can also been downloaded and preserved.
Archive Box can build full archives of the websites listed in your bookmarks, browser history, or from a list of custom URLs that you provide. In the rest of this post I’ll show you how you can set up and install Archive Box and start to archive your own pages.
Setting Up
Archive Box is written in Python and runs on Linux and Mac OS. It makes use of the native Linux/Mac programs like curl and wget to grab a lot of data so unlike many other Python tools it won’t run in Windows. If you want to use Archive Box in a Windows environment then you’ll need to install and run it with Docker as per these instructions here.
The latest version (0.4.21) of Archive Box is available via Pypi, so that’s what we’ll install in this guide. It requires Python 3.7 or higher to run. I use Linux or MacOS for most tools like this but Archive Box will also run on Windows provided that you have already installed Python/Pip.
To check your current version of Python 3 enter the console and type:
$ python3 -V
If the version is less than 3.7, you’ll need to install a more up to date version of Python.
Once you’ve installed Python 3.7 (or higher), you can install Archive Box directly from PyPi with the following command:
$ pip install archivebox
If you’re unfamiliar with Python and Pip, have a read of this post I wrote last year. If you’re using MacOS you can install Archive Box with Brew:
$ brew install archivebox
There’s also a Docker image available for Archive Box which means you can also run it on Windows, you’ll just need to set up Docker first. These days I prefer to use Docker images for OSINT tools but that’s for a future blog post.
Next you need to create a directory where your archive will be stored and complete the Archive Box setup there:
$ mkdir myarchive && cd myarchive $ archivebox init
Once installation has finished, you’ll be ready to start building your archive.
Basic Usage
All commands take the following format:
$ archivebox [command] [argument]
To archive a single webpage, use the following command:
$ archivebox add 'https://nixintel.info'
It’s also possible to add recursion to your request, so not only do you archive the page you specify, but Archive Box will also follow every link on the page and archive that too. The greater the depth, the further it will follow the links. Recursion can be added with the following option:
$ archivebox add 'https://nixintel.info' --depth=1
This will now archive the site and follow all the links within it to a depth of 1, and then archive all those pages too.
Viewing The Archive
Here’s the start of my new archive:
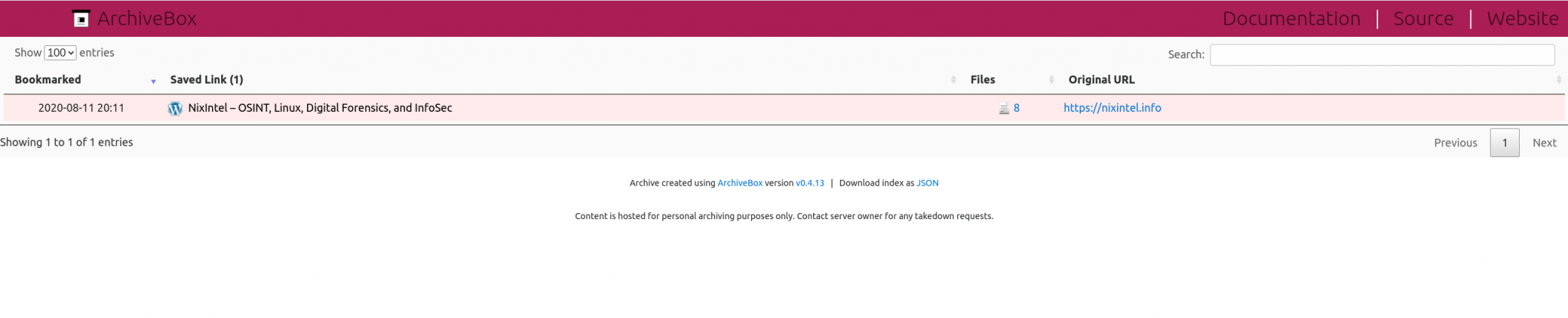
To view your archive, open your browser and navigate to the index.html file in archive folder you created. It’ll be something like /home/username/myarchive/index.html. The archive records the time you created it, the link that was saved, and the original URL. Clicking on “Files” will show just how powerful Archive Box is:
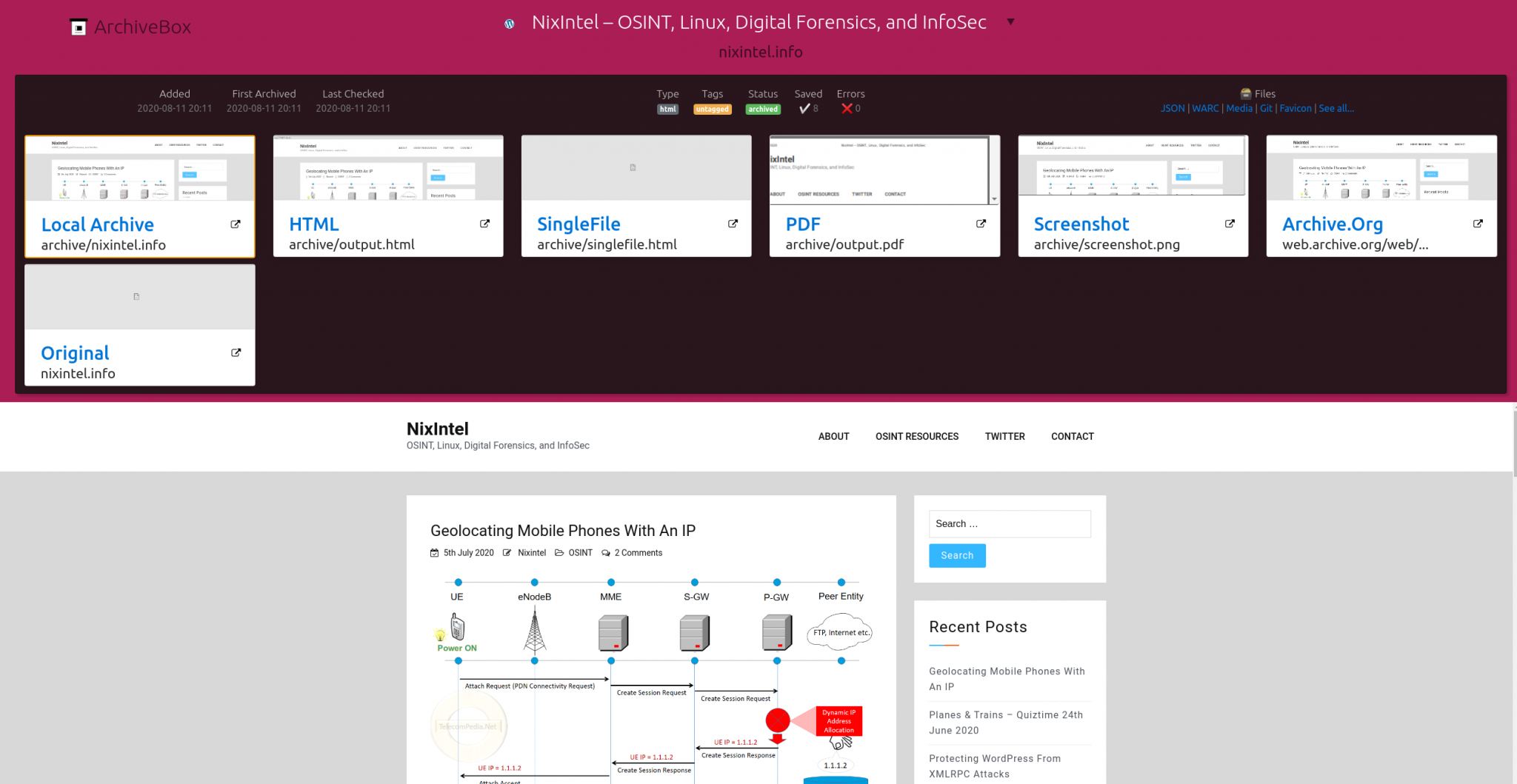
The front page of my website has been saved as an offline local archive (complete with all necessary JavaScript so the appearance is identical to the live version), as pure HTML/CSS, as a PDF, a PNG screenshot, and you’ll also notice that Archive Box has even archived a copy on the WayBack Machine too. So now I have a full working archive of my site saved locally on my machine. This is a much better way to preserve a webpage than with simple screenshots, and even if the original site were to disappear (I hope not) I’d still have a full offline copy to work with.
Archiving Multiple Websites
An archive with one site in it isn’t much fun. Fortunately Archive Box also makes it easy to archive multiple sites at once, either from a list of URLs, or from your browser’s saved bookmarks. To archive multiple websites, create a text file like this, with one URL on each line.
https://osintcurio.us https://bbc.co.uk/football https://theguardian.com
Then we enter the following command (assuming your URL list is in the same directory as your archive):
$ cat url_list.txt | archivebox add
After a few minutes, all the listed websites have been added to my offline archive in the same range of formats as before:

The archive of the BBC Football page shows the advantage of saving in multiple formats. The site features a lot of custom video streams that can’t really be archived offline, so the local archive looks a little odd:
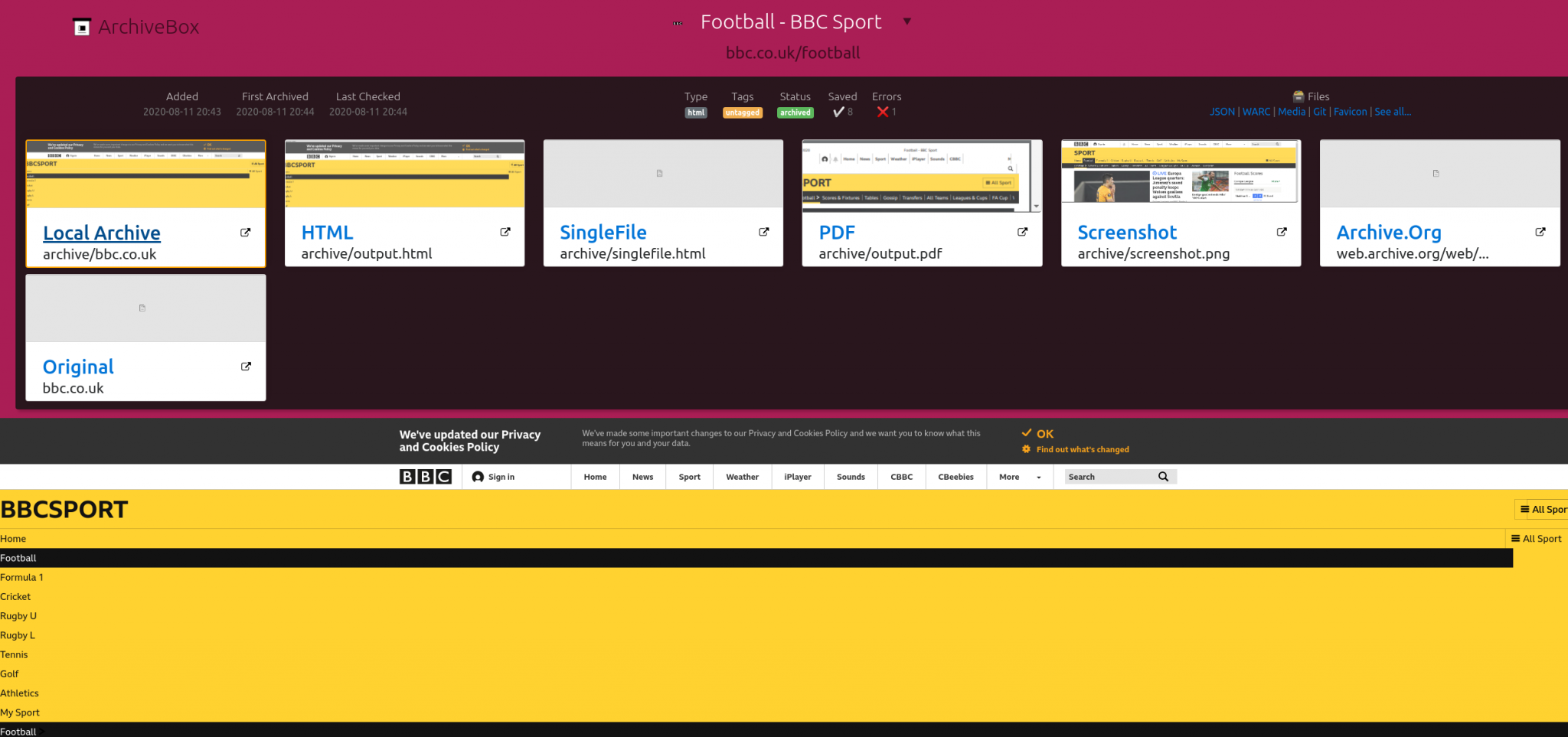
Despite this the fact that PDF and PNG versions of the site are also created means we can still see what the site was like at the time it was archived. You’ll also notice a limitation of the Wayback Machine that I mentioned earlier. If a site doesn’t want to be crawled by the Wayback Machine, the only thing that will be preserved is a 301 error. Archiving in multiple formats means that the chances of material being lost is significantly reduced.
Video Content
Archive Box uses YouTube-dl so that it can archive video content too. Let’s say that you want to add this OSINTCurious Ten Minute Tip to your archive. You can run the following command:
$ archivebox add https://www.youtube.com/watch?v=zo_geMvcOg8&feature=youtu.be
The entire 10 Minute Tip will now saved to your archive, including the video and audio files.
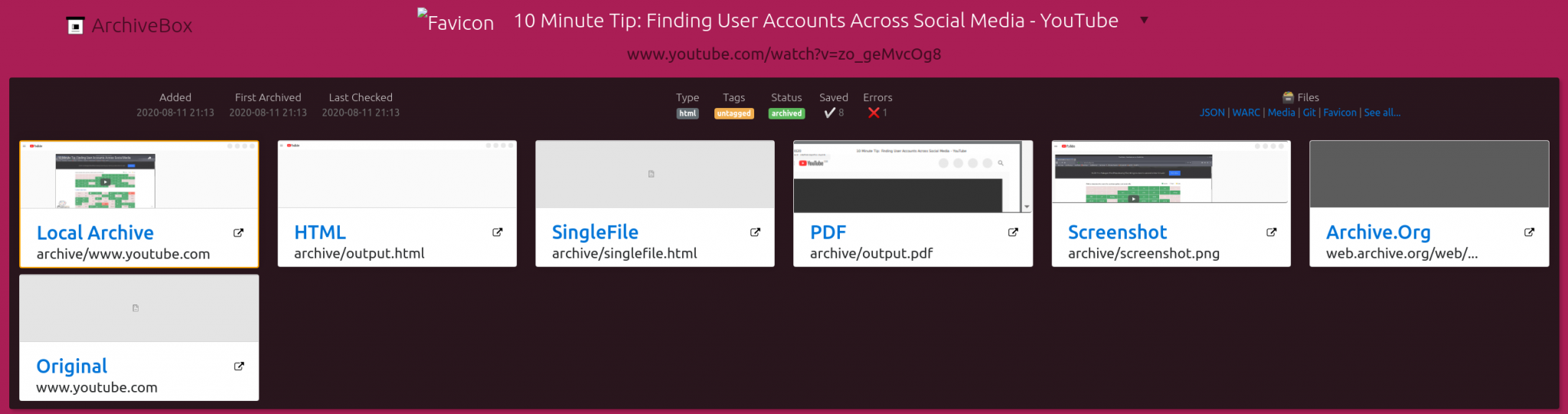
To access the archived video/audio, click on the “Media” link on the right. You’ll see that the video, audio and thumbnail content have all been archived and preserved offline:

Archiving Your Bookmarks
Archive Box also allows you to create archives of websites saved in your bookmarks. Simply export a list of bookmarks from your browser (see instructions here for Chrome and here for Firefox) as an HTML file and point Archive Box at it:
$ archivebox add /path/to/bookmarks.html
Conclusion
Being able to capture and preserve web content is a core skill for OSINT investigators. There are several technical challenges that make this difficult but Archive Box is a very effective way of gathering and preserving the information that you need.
Archive Box is in active development and it continues to receive new features and updates, so some elements of this post might become outdated in time. Follow @ArchiveBoxApp on Twitter for the latest updates.
Hello,
I’d like to have a Pi dedicated to this task, I will try to install archivebox on it. Do you know 22120 https://github.com/c9fe/22120
No I hadn’t but it looks good, I’ll check it out.
I’m dreaming, but I’d love a browser plugin so I can click a button and save to NAS.
Firefox plugin “save page we” does that.
Thanks for writing this! I’m the author (@pirate) on Github.
Our latest releases have lots of new features since this article was published, including:
– full-text search
– article text extraction with Readability
– Better HTML snapshots using SingleFile
– a new grid view UI
– better packaging with apt, brew, docker, pip, etc.
– lots of assorted bugfixes, new commands + CLI options, and small features
You can always find the latest release and changelog notes here: https://github.com/ArchiveBox/ArchiveBox/releases
Thanks for the update Nick, Archivebox is a great piece of software. I started writing this piece several months before I published it so a lot got out of date pretty quickly!
Pingback: NixIntel: Make Your Own Internet Archive With Archive Box | ResearchBuzz: Firehose
Pingback: Chinatown (NYC) Photography, Podcasts, Washington Newspapers, More: Wednesday ResearchBuzz, January 20, 2021 – ResearchBuzz
Pingback: Data Science newsletter – January 22, 2021 | Sports.BradStenger.com
hello!
Pingback: Cookies for Capture: Using ArchiveBox’s –cookie Option for Authenticated Web Content in OSINT – Argelius Labs